Local LLM Setup with CUDA, llama.cpp, and Qwen
Next to the neglected treadmill in the basement a physical server was setup for hosting a local LLM. Qwen3-Coder served by llama.cpp primarily used by Aider via the CLI of an M1 Mac Air. Also did a quick detour to open ports and config Cloudflare for usage remotely. Rolled that back for now and only use locally but will like open or use a CF tunnel in the future for remote access.
System
12GB VRAM Nvidia Card and 128GB RAM. Ubuntu 24.04.2 LTS installed.

CUDA
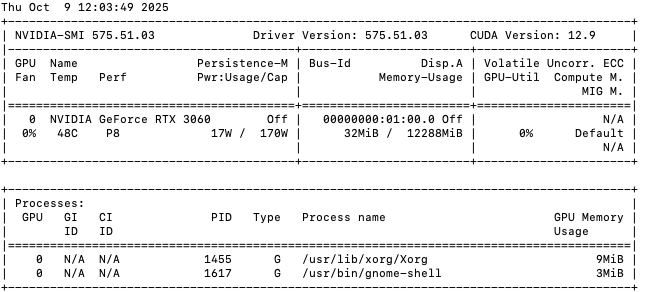
End result of installation shown below. No usable notes but history shows and number of sudo apt install and purges of nvidia packages.
llama.cpp
Cloned https://github.com/ggml-org/llama.cpp.git and compiled. Again, no usable notes but history shows gcc packages were installed/updated. Once compiled Qwen model was downloaded from huggingface and served using llama.cpp scripts.